Xiaoyi Han
Short Bio
My Name is Xiaoyi Han.
My research lies at the intersection of Computer Vision and Natural Language Processing, with a particular focus on Multi-Modal Learning (Scene Graph Generation). My research interests are broad, ranging from basic Computer Vision tasks such as Object Detection and Image Segmentation, to exploring the frontiers of Cross-Modal understanding and generation, such as Image Caption and Video Question Answering, etc.
News
- [Oct. 2024] My paper about Fire and Smoke Detection Method is accepted to ACM MM asia 2024.🔥
- [Jun. 2024] My paper about Fire and Smoke Detection Benchmark is accepted to PRCV 2025.🔥
Selected Publications [Google Scholar]
-
 acm mm asia
ACM Multimedia Asia Conference ((MM Asia), 2024.
acm mm asia
ACM Multimedia Asia Conference ((MM Asia), 2024. -
 prcv
Pattern Recognition and Computer Vision (PRCV), 2024.
prcv
Pattern Recognition and Computer Vision (PRCV), 2024.
Projects
-
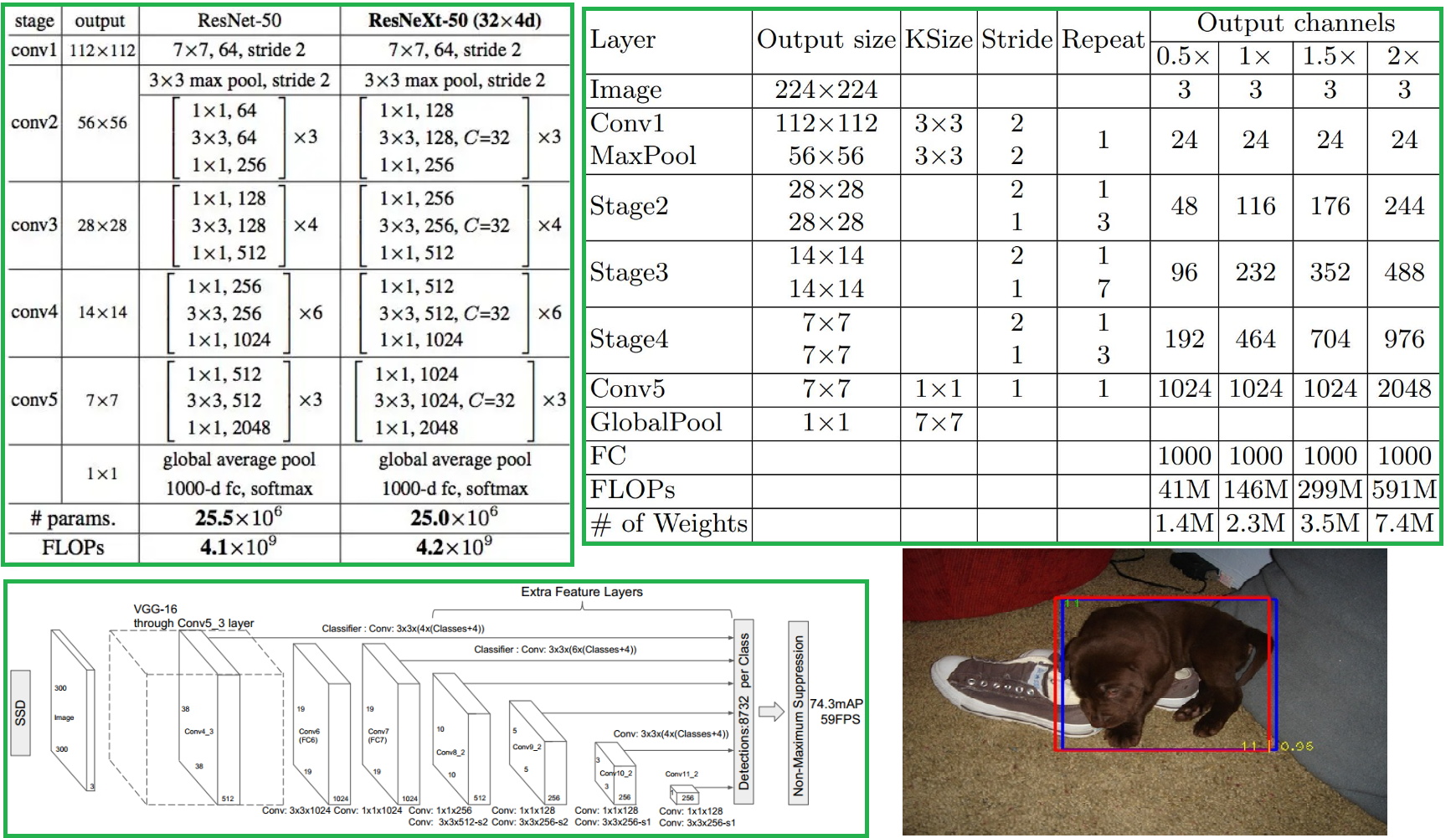 A Simple Computer Vision Project written with Pytorch (31 Github Stars)This project includes Image Classification and Object Detection tasks, and semantic segmentation task will be added later.
A Simple Computer Vision Project written with Pytorch (31 Github Stars)This project includes Image Classification and Object Detection tasks, and semantic segmentation task will be added later.
Honors and Awards
- [Jul. 2018] Outstanding Graduates of Beijing Ordinary Colleges and Universities.✨
- [Nov. 2016] Chinese National Scholarship for the 2015-2016 Academic Year.✨
Powered by Jekyll and Minimal Light theme.